In this short blog post, we’ll be expanding upon some of our core technology and our approach to molecular discovery for pesticides. In general, we view pesticide discovery as a search space problem, where we’re trying to optimize for multiple different (sometimes conflicting) properties of small molecules and peptides. We believe that foundational models have become powerful tools for predicting these different properties, and hence can be leveraged with generative pipelines to effectively find pesticides. We support this hypothesis by showing in-vitro data for pesticides discovered by our model, targeting Spodoptera Frugiperda, an invasive pest species that causes $10 billion worth of damages every year.
What are pesticides? Why do we care about them?
Pesticides are substances used to control and kill pests. The word ‘pests’ is a very broad one, and as such, pesticides is a ‘catch-all’ term for substances that are used to kill insects and control invasive weeds (herbicides). Pesticides are essential for 98% of all farmlands.
Good! Now that we’ve defined pesticides, let’s move on to why we care about them.
Pesticides are omnipresent in agriculture, and as a result, are a huge part of our food consumption. However, despite decades of research, farmers today are losing the same share of their crops to pests as they did 30 years ago. Pesticide usage has doubled per acre over the last three decades, yet crop losses have remained constant. As pests evolve and develop resistance, farmers are forced to use increasing amounts of pesticides to get the same results, damaging the environment and leading to even more pest resistance. At the same time, agricultural innovation has stagnated, with fewer than 20 new active ingredients approved in the past decade — down from 40 in the decade before that.
Our Approach
We believe very strongly in the bitter lesson; specifically that ‘general methods that leverage computation are ultimately the most effective, and by a large margin’. Instead of using human knowledge to generate proteins and small molecules on the basis of known or hypothesized properties, we leverage foundational models trained on massive amounts of data. We believe that such models innately capture comprehensive information about the modality that they’re working with.
On the basis of this hypothesis, we’ve built multiple models over the past year. We briefly describe the models and share some benchmarks/in-vitro data collected by our laboratory.
Atomwell
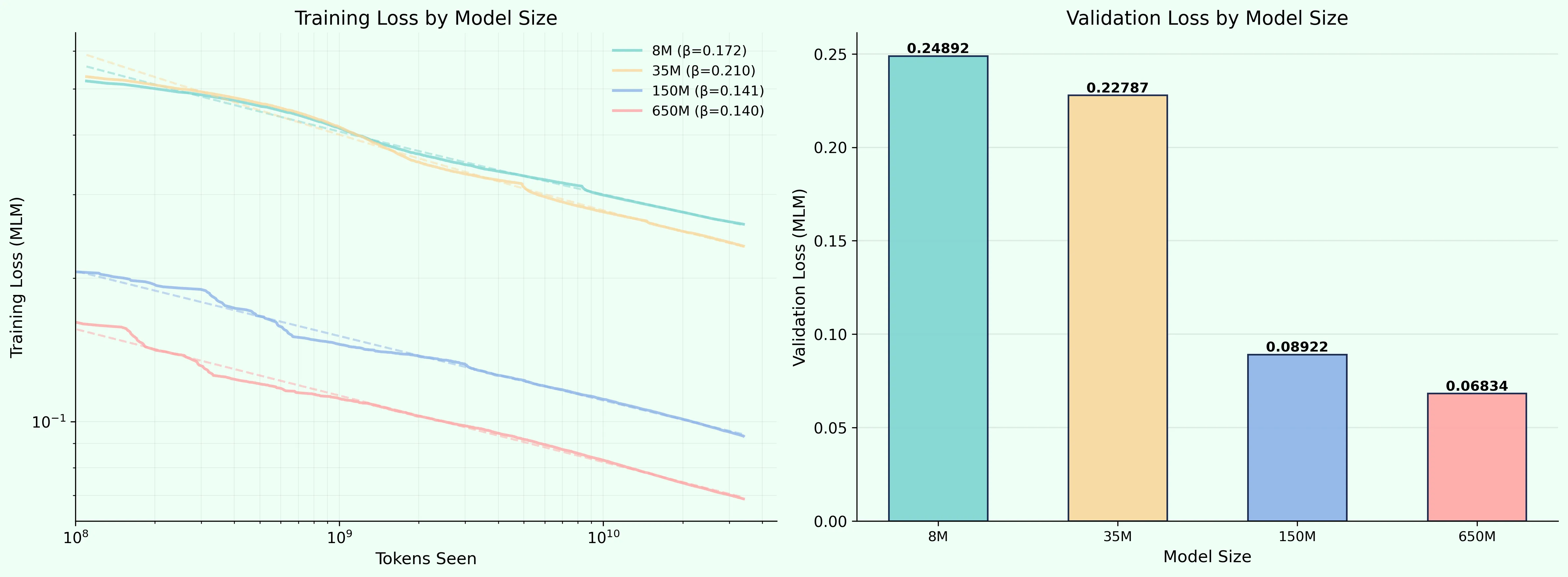
Atomwell is our unified, all-atom foundational model that deals with small molecules, proteins and nucleic acids. It’s a 150M parameter model trained on more than 50 billion tokens of FASTA and SMILES sequences. A diffusion language model, we’ve trained it using the D3PM paradigm, which enables the model to predict “clean” tokens given a timestep and a noised sequence.
This architectural choice of diffusion means that Atomwell is not only very good at predicting properties of small molecules and proteins for downstream tasks (via embeddings), but also excellent at conditional generation of proteins/small molecules given a motif/part of a sequence.
Atomwell is trained using Flash Attention, with sequence packing (concatenating smaller sequences into one large sequence to prevent wastage from <PAD> tokens). We edited the FA implementation of ESM2 to include support for not only sequence packing, but “batched sequence packing”, where the model is able to batch together sequences after concatenating smaller sequences into one.
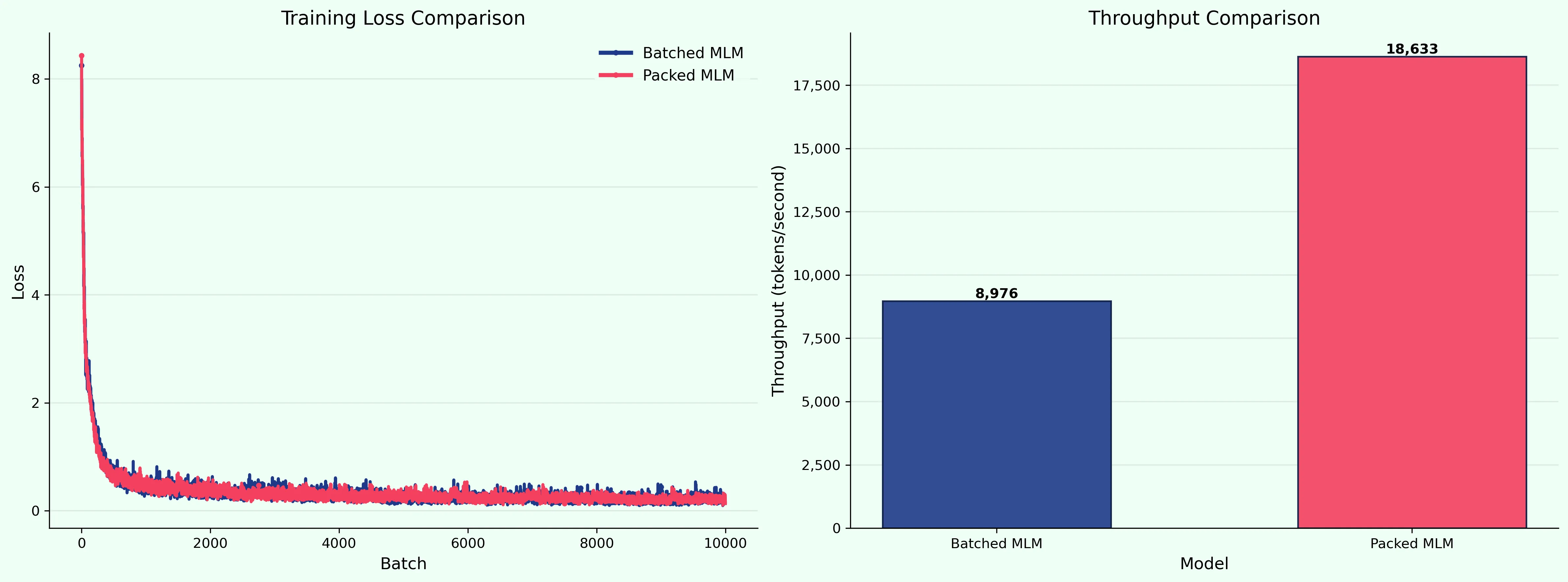
In addition to performing very well, we discover strong scaling laws for Atomwell. In the future, we plan to scale up Atomwell to more than a billion parameters, utilizing its embeddings for better downstream predictions.
Pairwell
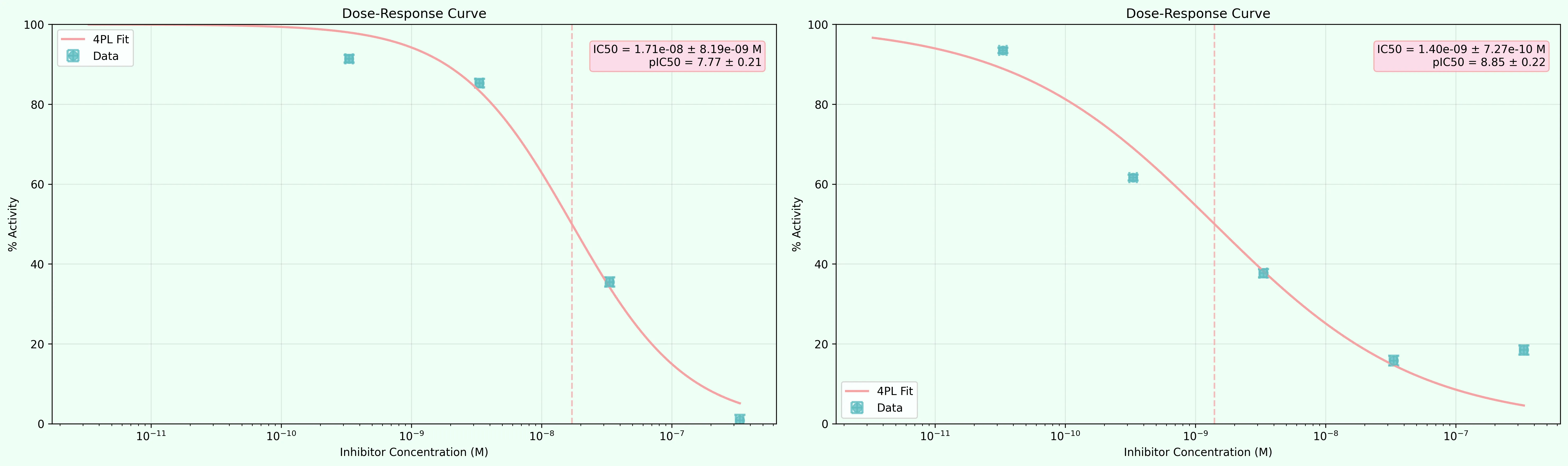
Pairwell is our unified model for protein-protein and protein-ligand binding with state-of-the-art generalized uncertainty quantification. Current protein-ligand binding models generalize poorly across protein and chemical space. Without uncertainty quantification, the model confidently predicts in regimes where it has no training data, producing false leads. With calibrated uncertainty estimates, we know precisely when predictions are unreliable. This guides our experimental strategy: we generate assay data in underrepresented regions where uncertainty is high, systematically expanding the model’s operating range across the full chemical and protein space relevant to pesticide discovery.
Using the embeddings generated from Atomwell and the Pairwell architecture, we were able to find novel small molecules and peptides in-silico targeting Spodoptera Frugiperda, an invasive pest species that causes $10 billion worth of damages each year. We tested our in-silico hits in our lab in Santa Clara, California, and found peptides and small molecules binding with nanomolar affinity to our target.
Foldwell
Foldwell is our state-of-the-art protein structure prediction model that runs 4x faster than AlphaFold3. We use it extensively to not only validate our targets and identify binding sites in target proteins, but also to ensure that our designed proteins fold correctly before we commit resources to experimental validation.
The dramatic speedup in Foldwell was achieved through strategic modifications to the diffusion trunk of open-source models such as Boltz. By optimizing the attention mechanisms in the diffusion trunk and implementing more efficient sampling strategies during the denoising steps, we were able to maintain prediction accuracy while dramatically reducing inference time.
Open Source
We’re huge fans of open source! In the past year, we’ve released PLAPT and APPT, two of our smaller models for predicting binding affinity for proteins and small molecules. Additionally, we’ve also open-sourced their training datasets, making this the biggest data source for protein-protein binding data anywhere. This has enabled multiple researchers to train multiple models of their own.
We’ll also be open-sourcing our findings on best practices for building the most performant language models, including multiple mechanistic interpretability findings for our models.